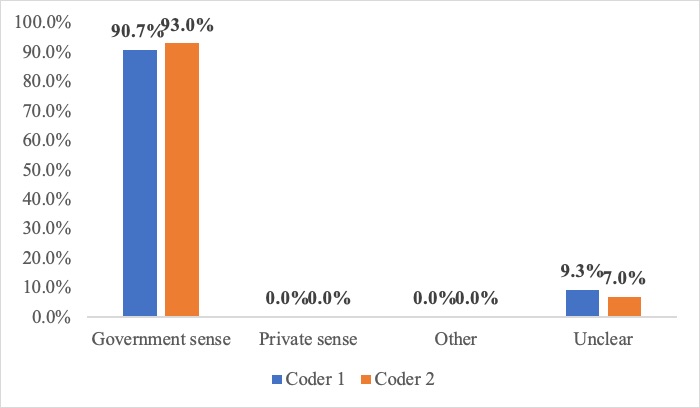
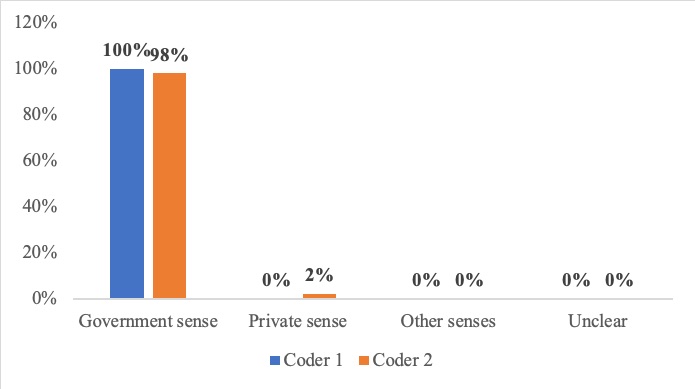
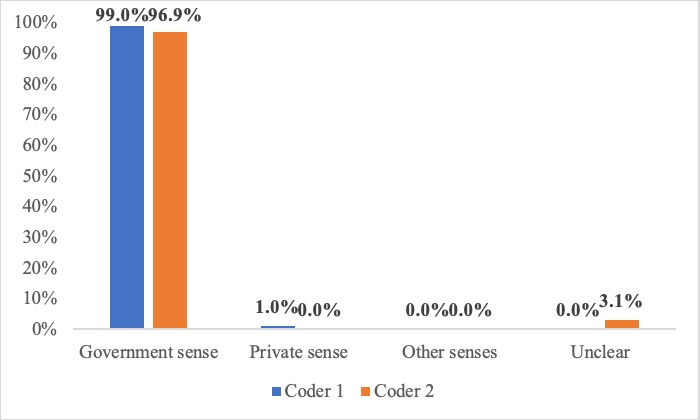
Why do parties—even sophisticated ones—draft contracts that are vague or incomplete? Many others have tackled this question, but this Article argues that there is an overlooked, common, and powerful reason for contractual gaps. Using original interviews with dealmakers, it introduces a theory of “collaborative intent” to show that the bureaucratic deal-building process within companies can help explain why contracts are incomplete, vague, and otherwise seemingly irrational. The institutional details of dealmaking are important but understudied, and have wide-ranging implications for contract theory, design, and interpretation.
This Article makes three contributions to the literature. First, using original interviews with in-house dealmakers, it provides the literature’s first account of how deals are made within companies. Both economists and legal scholars have tackled the puzzle of incomplete contracting, but leading explanations overlook the critical influence of companies’ internal deal-building process. Unlike individuals who enter into contracts, sophisticated business parties do not have monolithic intent. Instead, even before taking a seat at the negotiation table, business parties engage in a complex, internal bargaining process that requires many intra-corporate constituencies to weigh in and sign off on the deal. The result is that sophisticated business parties bring multiple agendas to the negotiation table, and those agendas are reflected in the contract. Second, collaboration complicates intent, especially for sophisticated parties. Rather than being the result of rational, considered contract design, contractual gaps may be mere byproducts of the contract-shepherding process within the firm. Finally, this Article offers practical guidance to courts and contract designers about the overlooked and rampant intra-corporate bargaining and pork-barreling process. It helps them account for collaborative intent in ex ante contract design and ex post contract enforcement.
Introduction
Four weeks before Halloween in 2018, a Delaware Chancery Court decision spooked the corporate world. In an unprecedented move, the court released German pharmaceutical giant Fresenius from its $4.75 billion contract to buy U.S. generic drug manufacturer Akorn based on a contract term called the material adverse change clause.1 1.Akorn, Inc. v. Fresenius Kabi AG, No. CV 2018-0300, 2018 WL 4719347 (Del. Ch. Oct. 1, 2018), aff’d, 198 A.3d 724 (Del. 2018).Show More The decision in Akorn, Inc. v. Fresenius Kabi AG was the first time Delaware courts had found that a company triggered a material adverse change clause, and it sparked a storm of anxiety and commentary.2 2.Many major firms issued client alerts, immediately digesting the landmark case for their clients. See, e.g., David Leinwand, James E. Langston & Mark E. McDonald, Akorn v. Fresenius: A MAC in Delaware, Cleary Gottlieb Steen & Hamilton LLP (Oct. 11, 2018), https://www.clearymawatch.com/2018/10/akorn-v-fresenius-mac-delaware [https://perma.cc/43KW-C54E]; Chris Gorman & Lisa Richards, Akorn v. Fresenius: Important Practical Lessons from First-Ever Material Adverse Effect, Fenwick & West LLP (Oct. 24, 2018), https://www.fenwick.com/publications/pages/akorn-v-fresenius-important-practical-lessons-from-first-ever-material-adverse-effect.aspx [https://perma.cc/9KPX-75MZ]; Peter A. Atkins & Edward B. Micheletti, ‘Reasonable Efforts’ Clauses in Delaware: One Size Fits All, Unless . . ., Skadden, Arps, Slate, Meagher & Flom LLP (Nov. 1, 2018), https://www.skadden.com/insights/publications/2018/10/reasonable-efforts-clauses-in-delaware [https://perma.cc/JR7Z-FYAP]; Grant J. Esposito, David J. Fioccola & Robert W. May, Delaware Court of Chancery Finds a Material Adverse Event and Excuses Buyer from Obligation to Close in Akorn v. Fresenius Kabi AG, Morrison & Foerster LLP (Oct. 9, 2018), https://www.mofo.com/resources/insights/181009-delaware-material-adverse-event.html [https://perma.cc/FE72-NR7Q].Show More
In every merger and acquisition (“M&A”) deal, there is a material adverse change provision: a long-winded, heavily negotiated provision choked with exceptions and caveats. Material adverse change provisions almost always say the same thing: that if something huge and unexpected happens between the contract’s signing and the deal’s closing, one or both parties can back out of the deal.3 3.Albert Choi & George Triantis, Strategic Vagueness in Contract Design: The Case of Corporate Acquisitions, 119 Yale L.J. 848, 854 (2010) [hereinafter Choi & Triantis, Strategic Vagueness](defining a material adverse change clause in a contract as one that “permit[s] the buyer to avoid the closing of a deal if a material change has occurred in the financial condition, assets, liabilities, business, or operations of the target firm”).Show More And, perhaps most surprisingly, despite the long negotiations and dense legalese, material adverse change provisions are vague.4 4.Id. at 853 (noting that material adverse change clauses are vague, but “among the most heavily negotiated nonprice terms”).Show More
Vague provisions like these are common but surprising. In M&A contracts, for example, parties routinely haggle over whether they will use “best efforts,” “commercially reasonable best efforts,” or “reasonable best efforts” to accomplish certain tasks—and each of these standards will be left unspecified and unquantified.5 5.See Scot Baker & Albert Choi, Contract’s Role in Relational Contract, 101 Va. L. Rev. 559, 565 (2015) (describing the common “best efforts” provisions as “a fault-based and open-ended standard”); Anthony J. Casey & Anthony Niblett, Self-Driving Contracts, 43 J. Corp. L. 1, 8 (2017) (“[Parties can choose to] use a vague standard that also requires a court to fill in the details after the fact. This could be a clause that requires something like ‘reasonable efforts,’ ‘best efforts,’ or ‘commercially reasonable efforts.’”); Victor P. Goldberg, In Search of Best Efforts: Reinterpreting Bloor v. Falstaff, 44 St. Louis L. Rev. 1465, 1465 (2000) (“When contracting parties cannot quite define their obligations, they often resort to placeholder language, like ‘best efforts.’”); Robert E. Scott, Contract Design and the Shading Problem, 99 Marq. L. Rev. 1, 20 (2015) (“[I]n the past fifty years, parties have increasingly inserted vague terms such as ‘best efforts,’ reasonable best efforts,’ or ‘commercially reasonable best efforts’ as modifiers that are combined with specific of precise performance obligations under the contract.”). The contracts law case Bloor v. Falstaff, 601 F.2d 609 (2d Cir. 1979), is another famous case about best efforts clauses.Show More In debt contracts, borrowers promise to let lenders conduct “routine” inspections, without specifying what is routine.6 6.In A. Gay Jenson Farms Co. v. Cargill, 309 N.W.2d 285 (Minn. 1981), the well-known agency law case, for example, large international conglomerate Cargill lent money to a small Minnesota grain elevator operator, in part on the condition that Cargill could conduct routine inspections of the grain elevator. The intrusive nature of the inspections became one of the reasons that the grain elevator operator’s other creditors later sued Cargill, arguing that the grain elevator operator was an agent of Cargill and that Cargill should be liable for the operator’s debts. Id. at 290–91.Show More In just about any corporate contract, parties promise “material” compliance or compliance that does not rise to a “material adverse effect,” again without specifying what those thresholds might mean.7 7.Robert Malionek & Jon Weichselbaum, Five Keys to Analyzing a Material Adverse Effect, N.Y.L.J. (Mar. 6, 2019), https://www.lw.com/thoughtLeadership/five-keys-analyzing-material-adverse-effect-ny-law-journal [https://perma.cc/TM95-FQKH] (noting that “[m]ateriality is both qualitative and quantitative” and that in M&A contracts, representations can be made “that reasonably would be expected to result in [a material adverse change]”).Show More In each of these circumstances, sophisticated parties, who have both the technical sophistication and financial means to draft specific, complete provisions, choose instead to embrace vague, incomplete ones.
The persistence of vague provisions, incomplete contracts, and other such contractual oddities has long plagued both legal scholars and economists—and neither literature has a shortage of explanations. Economist and Nobel Prize laureate Oliver Hart famously notes that contracts are necessarily incomplete: there are no parties, no circumstances, where every contingency can be thought of and thought out ex ante.8 8.See Oliver Hart, The Nobel Prize, https://www.nobelprize.org/prizes/economic-sciences/2016/hart/facts/ [https://perma.cc/E6MG-HZY4] (last visited Nov. 10, 2021) (“In the mid-1980s, [Hart] contributed to the theory of incomplete contracts. . . . These analyses have been significant for, among other things, governance of companies and the design of laws and institutions.”); Oliver Hart & John Moore, Foundations of Incomplete Contracts, 66 Rev. Econ. Stud. 115 (1999) [hereinafter Hart & Moore, Foundations of Incomplete Contracts](developing a model for the idea that contracts are incomplete); Oliver D. Hart, Incomplete Contracts and the Theory of the Firm, 4 J.L. Econ. & Org. 119 (1988); Oliver Hart, Dep’t of Econ., Harvard Univ., Incomplete Contracts and Control, Nobel Prize Lecture 372–73 (Dec. 8. 2016), https://www.nobelprize.org/uploads/2018/06/hart-lecture.pdf [https://perma.cc/7TKE-49TD] [hereinafter Hart, Incomplete Contracts & Control](noting that, although economists spent many decades working on questions involving complete contracts, “[a]ctual contracts are not like this, as lawyers have recognized for some time. They are poorly worded, ambiguous, and leave out important things. They are incomplete.”).Show More Many scholars have argued convincingly that vagueness in contracts—especially in contracts between sophisticated business parties—is intentional and rational: provisions that are rarely litigated but expensive to negotiate, such as material adverse effect provisions, are particularly well-suited to vagueness.9 9.Choi & Triantis, Strategic Vagueness, supra note 3, at 852–53, 855 (arguing that parties can use vague contract provisions efficiently—for example, material adverse change clauses in acquisition agreements may remain vague because they are rarely litigated); Robert E. Scott & George G. Triantis, Anticipating Litigation in Contract Design, 115 Yale L.J. 814, 818–22 (2006) [hereinafter Scott & Triantis, Anticipating Litigation] (examining the efficiency of investment in the design and enforcement phases of the contracting process and arguing that parties can lower overall contracting costs by using vague contract terms ex ante and shifting investment to the ex post enforcement phase); Robert E. Scott & George G. Triantis, Incomplete Contracts and the Theory of Contract Design, 56 Case W. Res. L. Rev. 187, 195–96 (2005) (considering the role of litigation in motivating contract design).Show More Still others have argued that contracts do not need to be complete or specific. Community and industry norms can and do fill the gap where contracts are vague—and sometimes even when contracts do not even exist.10 10.See Ronald J. Gilson, Charles Sabel & Robert E. Scott, Braiding: The Interaction of Formal and Informal Contracting in Theory, Practice, and Doctrine, 110 Colum. L. Rev. 1377, 1398–99 (2010) [hereinafter Gilson et al., Braiding] (discussing the “rivalry” between formal and informal enforcement for contracts and noting that the two can substitute for each other or complement each other); see also Lisa Bernstein, Opting Out of the Legal System: Extralegal Contractual Relations in the Diamond Industry, 21 J. Legal Stud. 115, 121–24 (1992) [hereinafter Bernstein, Opting Out] (describing trade association enforcement of contractual breaches); Lisa Bernstein, Private Commercial Law in the Cotton Industry: Creating Cooperation Through Rules, Norms, and Institutions, 99 Mich. L. Rev. 1724, 1725 (2001) (describing the cotton industry’s alternative system of enforcement to the typical legal system).Show More And, in those cases, it is the threat of informal sanctions, such as loss of reputation, that curbs bad behavior, even without a legally binding contract.11 11.Informal sanctions are particularly effective in small, tight-knit communities where parties have many points of contact. A robust literature has documented the role of norms and informal sanctions in a variety of interesting settings. See Robert C. Ellickson, Of Coase and Cattle: Dispute Resolution Among Neighbors in Shasta County, 38 Stan. L. Rev. 623, 628, 677 (1986) [hereinafter Ellickson, Of Coase and Cattle] (describing how rural cattle ranchers in Shasta County, California, abide by norms rather than rules and how animal trespass disputes are settled by self-help rather than formal legal enforcement mechanisms); Robert C. Ellickson, A Hypothesis of Wealth-Maximizing Norms: Evidence from the Whaling Industry, 5 J.L. Econ. & Org. 83, 84–85 (1989) (presenting evidence of informal enforcement—norms—overtaking formal enforcement in the whaling industry); Peter T. Leeson, An-arrgh-chy: The Law and Economics of Pirate Organization, 115 J. Pol. Econ. 1049, 1051 (2007) (describing the extralegal systems that pirates developed to provide checks on captain predation and to “create piratical law and order”); Bernstein, Opting Out, supra note 10, at 124 (describing how a diamond-merchant trade association in New York City helps to enforce contracts); Gillian K. Hadfield & Iva Bozovic, Scaffolding: Using Formal Contracts to Support Informal Relations in Support of Innovation, 2016 Wis. L. Rev. 981, 987, 1017 (describing the way in which commercial contracting parties across a variety of industries use a mix of formal and informal contracts to support their business relationships); Lisa Bernstein, Beyond Relational Contracts: Social Capital and Network Governance in Procurement Contracts, 7 J. Legal Analysis 561, 562 (2015) (describing how original equipment manufacturers in the Midwest have used a mix of formal contracts, relational contracts, and other tools to build and support their business relationships); Jonathan M. Barnett, Hollywood Deals: Soft Contracts for Hard Markets, 64 Duke L.J. 605, 607 (2015) (discussing the use of non-binding agreements—or “soft contracts”—in modern Hollywood filmmaking).Show More
In many contexts, these explanations are convincing. Consider a simple apartment lease signed between one landlord and one tenant. Rather than spending a lot of time up-front discussing the specific condition in which the tenant needs to leave the apartment at move-out, the parties might simply decide to agree to the vague provision that the tenant needs to leave the apartment “clean.” The law and economics view explains this decision well: in most cases, the tenant leaves the place clean enough, and the parties will never have to haggle over the details upon move-out. Relational contracting theory also explains the vagueness well: the landlord doesn’t need to be too specific about cleanliness because the tenant relies on the landlord to give her a good reference for her next apartment rental.
But while existing explanations work well for simple, two-party contracts, and do some work in explaining sophisticated-party contracting, they fall short.12 12.In previous work, for example, I explored the puzzle of term sheets in M&A contracting. Term sheets—short, nonbinding precursors to a full-fledged M&A contract—are not contracts and are not legally binding or enforceable. Parties to term sheets do not operate in the tight-knit communities where informal sanctions are known to work. Nonetheless, once parties sign them, they behave as though bonded. Why do nonbinding term sheets have binding power? See Cathy Hwang, Deal Momentum, 65 UCLA L. Rev. 376, 380 (2018) (describing how deal lawyers use preliminary agreements in M&A deals); Cathy Hwang, Faux Contracts, 105 Va. L. Rev. 1025, 1056 (2019) [hereinafter, Hwang, Faux Contracts] (describing how M&A deals create small relational ecosystems in which both the contracting parties and their agents are incentivized to engage in consummate, rather than perfunctory, performance).Show More Certainly cost-benefit analysis and informal sanctions account for some contractual oddities—but not all. This Article offers a friendly addendum to those pathbreaking explanations: collaborative intent.
At its core, collaborative intent relies on a simple idea: businesses are not monoliths. They contain many divisions, departments, operational groups, and other constituencies. This idea is well-understood in the literature—even Ronald Coase’s seminal work on the boundary of the firm assumed that companies would contain multiple different groups within it.13 13.Ronald H. Coase, The Nature of the Firm, 16 Economica 386, 390 (1937) (posing and discussing the “boundaries of the firm” question: When should individuals be expected to form firms, and when should they be expected to cooperate through contract?).Show More Collaborative intent takes this idea a step further: it explicitly recognizes that each module within a company has its own purpose and, correspondingly, its own incentives, goals, limitations, and preferences. Internal constituencies often have a chance to veto—or at least weigh in on—both the substance and form of a proposed deal. By the time a company brings its intent to the negotiating table, that intent reflects the result of a consensus-building process within the company—in other words, the company brings what this Article calls its collaborative intent.
That collaborative intent in turn helps to account for many contractual oddities. Contracts that result from this kind of institutional collaboration are not necessarily rational, intentional, or carefully considered. Instead, they are amalgamations of many preferences within each deal party and result from the consensus-building process of getting the deal through a bureaucracy.
This Article provides a layered account of collaborative intent and its impact on deals and contracts, and proceeds as follows. Part I sets the stage. It shows how current contract theory does not account for the dealmaking process within firms. Part II presents the theory and evidence of collaborative intent. It uses two dozen original interviews with in-house dealmakers to show how the process of building consensus for a deal within the firm impacts contractual form and structure. Interview participants brought experience from a variety of industries, ranging from technology to hospitality to gaming, and uniformly reported that dealmaking within the firm is a collaborative exercise: it requires vote-whipping, pork-barreling, and balancing the needs of various constituencies into a coherent but multifaceted “intent.” Part III turns to implications. Existing literature overlooks the institutional details that impact contract design. Collaborative intent injects important and overlooked nuance and helps to build out a nuanced account of dealmaking that can help shape contract theory, enforcement, and design.
- Akorn, Inc. v. Fresenius Kabi AG, No. CV 2018-0300, 2018 WL 4719347 (Del. Ch. Oct. 1, 2018), aff’d, 198 A.3d 724 (Del. 2018). ↑
- Many major firms issued client alerts, immediately digesting the landmark case for their clients. See, e.g., David Leinwand, James E. Langston & Mark E. McDonald, Akorn v. Fresenius: A MAC in Delaware, Cleary Gottlieb Steen & Hamilton LLP (Oct. 11, 2018), https://www.clearymawatch.com/2018/10/akorn-v-fresenius-mac-delaware [https://perma.cc/43KW-C54E]; Chris Gorman & Lisa Richards, Akorn v. Fresenius: Important Practical Lessons from First-Ever Material Adverse Effect, Fenwick & West LLP (Oct. 24, 2018), https://www.fenwick.com/publications/pages/akorn-v-fresenius-important-practical-lessons-from-first-ever-material-adverse-effect.aspx [https://perma.cc/9KPX-75MZ]; Peter A. Atkins & Edward B. Micheletti, ‘Reasonable Efforts’ Clauses in Delaware: One Size Fits All, Unless . . ., Skadden, Arps, Slate, Meagher & Flom LLP (Nov. 1, 2018), https://www.skadden.com/insights/publications/2018/10/reasonable-efforts-clauses-in-delaware [https://perma.cc/JR7Z-FYAP]; Grant J. Esposito, David J. Fioccola & Robert W. May, Delaware Court of Chancery Finds a Material Adverse Event and Excuses Buyer from Obligation to Close in Akorn v. Fresenius Kabi AG, Morrison & Foerster LLP (Oct. 9, 2018), https://www.mofo.com/resources/insights/181009-delaware-material-adverse-event.html [https://perma.cc/FE72-NR7Q]. ↑
- Albert Choi & George Triantis, Strategic Vagueness in Contract Design: The Case of Corporate Acquisitions, 119 Yale L.J. 848, 854 (2010) [hereinafter Choi & Triantis, Strategic Vagueness] (defining a material adverse change clause in a contract as one that “permit[s] the buyer to avoid the closing of a deal if a material change has occurred in the financial condition, assets, liabilities, business, or operations of the target firm”). ↑
- Id. at 853 (noting that material adverse change clauses are vague, but “among the most heavily negotiated nonprice terms”). ↑
- See Scot Baker & Albert Choi, Contract’s Role in Relational Contract, 101 Va. L. Rev. 559, 565 (2015) (describing the common “best efforts” provisions as “a fault-based and open-ended standard”); Anthony J. Casey & Anthony Niblett, Self-Driving Contracts, 43 J. Corp. L. 1, 8 (2017) (“[Parties can choose to] use a vague standard that also requires a court to fill in the details after the fact. This could be a clause that requires something like ‘reasonable efforts,’ ‘best efforts,’ or ‘commercially reasonable efforts.’”); Victor P. Goldberg, In Search of Best Efforts: Reinterpreting Bloor v. Falstaff, 44 St. Louis L. Rev. 1465, 1465 (2000) (“When contracting parties cannot quite define their obligations, they often resort to placeholder language, like ‘best efforts.’”); Robert E. Scott, Contract Design and the Shading Problem, 99 Marq. L. Rev. 1, 20 (2015) (“[I]n the past fifty years, parties have increasingly inserted vague terms such as ‘best efforts,’ reasonable best efforts,’ or ‘commercially reasonable best efforts’ as modifiers that are combined with specific of precise performance obligations under the contract.”). The contracts law case Bloor v. Falstaff, 601 F.2d 609 (2d Cir. 1979), is another famous case about best efforts clauses. ↑
- In A. Gay Jenson Farms Co. v. Cargill, 309 N.W.2d 285 (Minn. 1981), the well-known agency law case, for example, large international conglomerate Cargill lent money to a small Minnesota grain elevator operator, in part on the condition that Cargill could conduct routine inspections of the grain elevator. The intrusive nature of the inspections became one of the reasons that the grain elevator operator’s other creditors later sued Cargill, arguing that the grain elevator operator was an agent of Cargill and that Cargill should be liable for the operator’s debts. Id. at 290–91. ↑
- Robert Malionek & Jon Weichselbaum, Five Keys to Analyzing a Material Adverse Effect, N.Y.L.J. (Mar. 6, 2019), https://www.lw.com/thoughtLeadership/five-keys-analyzing-material-adverse-effect-ny-law-journal [https://perma.cc/TM95-FQKH] (noting that “[m]ateriality is both qualitative and quantitative” and that in M&A contracts, representations can be made “that reasonably would be expected to result in [a material adverse change]”). ↑
- See Oliver Hart, The Nobel Prize, https://www.nobelprize.org/prizes/economic-sciences/2016/hart/facts/ [https://perma.cc/E6MG-HZY4] (last visited Nov. 10, 2021) (“In the mid-1980s, [Hart] contributed to the theory of incomplete contracts. . . . These analyses have been significant for, among other things, governance of companies and the design of laws and institutions.”); Oliver Hart & John Moore, Foundations of Incomplete Contracts, 66 Rev. Econ. Stud. 115 (1999) [hereinafter Hart & Moore, Foundations of Incomplete Contracts] (developing a model for the idea that contracts are incomplete); Oliver D. Hart, Incomplete Contracts and the Theory of the Firm, 4 J.L. Econ. & Org. 119 (1988); Oliver Hart, Dep’t of Econ., Harvard Univ., Incomplete Contracts and Control, Nobel Prize Lecture 372–73 (Dec. 8. 2016), https://www.nobelprize.org/uploads/2018/06/hart-lecture.pdf [https://perma.cc/7TKE-49TD] [hereinafter Hart, Incomplete Contracts & Control] (noting that, although economists spent many decades working on questions involving complete contracts, “[a]ctual contracts are not like this, as lawyers have recognized for some time. They are poorly worded, ambiguous, and leave out important things. They are incomplete.”). ↑
- Choi & Triantis, Strategic Vagueness, supra note 3, at 852–53, 855 (arguing that parties can use vague contract provisions efficiently—for example, material adverse change clauses in acquisition agreements may remain vague because they are rarely litigated); Robert E. Scott & George G. Triantis, Anticipating Litigation in Contract Design, 115 Yale L.J. 814, 818–22 (2006) [hereinafter Scott & Triantis, Anticipating Litigation] (examining the efficiency of investment in the design and enforcement phases of the contracting process and arguing that parties can lower overall contracting costs by using vague contract terms ex ante and shifting investment to the ex post enforcement phase); Robert E. Scott & George G. Triantis, Incomplete Contracts and the Theory of Contract Design, 56 Case W. Res. L. Rev. 187, 195–96 (2005) (considering the role of litigation in motivating contract design). ↑
- See Ronald J. Gilson, Charles Sabel & Robert E. Scott, Braiding: The Interaction of Formal and Informal Contracting in Theory, Practice, and Doctrine, 110 Colum. L. Rev. 1377, 1398–99 (2010) [hereinafter Gilson et al., Braiding] (discussing the “rivalry” between formal and informal enforcement for contracts and noting that the two can substitute for each other or complement each other); see also Lisa Bernstein, Opting Out of the Legal System: Extralegal Contractual Relations in the Diamond Industry, 21 J. Legal Stud. 115, 121–24 (1992) [hereinafter Bernstein, Opting Out] (describing trade association enforcement of contractual breaches); Lisa Bernstein, Private Commercial Law in the Cotton Industry: Creating Cooperation Through Rules, Norms, and Institutions, 99 Mich. L. Rev. 1724, 1725 (2001) (describing the cotton industry’s alternative system of enforcement to the typical legal system). ↑
- Informal sanctions are particularly effective in small, tight-knit communities where parties have many points of contact. A robust literature has documented the role of norms and informal sanctions in a variety of interesting settings. See Robert C. Ellickson, Of Coase and Cattle: Dispute Resolution Among Neighbors in Shasta County, 38 Stan. L. Rev. 623, 628, 677 (1986) [hereinafter Ellickson, Of Coase and Cattle] (describing how rural cattle ranchers in Shasta County, California, abide by norms rather than rules and how animal trespass disputes are settled by self-help rather than formal legal enforcement mechanisms); Robert C. Ellickson, A Hypothesis of Wealth-Maximizing Norms: Evidence from the Whaling Industry, 5 J.L. Econ. & Org. 83, 84–85 (1989) (presenting evidence of informal enforcement—norms—overtaking formal enforcement in the whaling industry); Peter T. Leeson, An-arrgh-chy: The Law and Economics of Pirate Organization, 115 J. Pol. Econ. 1049, 1051 (2007) (describing the extralegal systems that pirates developed to provide checks on captain predation and to “create piratical law and order”); Bernstein, Opting Out, supra note 10, at 124 (describing how a diamond-merchant trade association in New York City helps to enforce contracts); Gillian K. Hadfield & Iva Bozovic, Scaffolding: Using Formal Contracts to Support Informal Relations in Support of Innovation, 2016 Wis. L. Rev. 981, 987, 1017 (describing the way in which commercial contracting parties across a variety of industries use a mix of formal and informal contracts to support their business relationships); Lisa Bernstein, Beyond Relational Contracts: Social Capital and Network Governance in Procurement Contracts, 7 J. Legal Analysis 561, 562 (2015) (describing how original equipment manufacturers in the Midwest have used a mix of formal contracts, relational contracts, and other tools to build and support their business relationships); Jonathan M. Barnett, Hollywood Deals: Soft Contracts for Hard Markets, 64 Duke L.J. 605, 607 (2015) (discussing the use of non-binding agreements—or “soft contracts”—in modern Hollywood filmmaking). ↑
- In previous work, for example, I explored the puzzle of term sheets in M&A contracting. Term sheets—short, nonbinding precursors to a full-fledged M&A contract—are not contracts and are not legally binding or enforceable. Parties to term sheets do not operate in the tight-knit communities where informal sanctions are known to work. Nonetheless, once parties sign them, they behave as though bonded. Why do nonbinding term sheets have binding power? See Cathy Hwang, Deal Momentum, 65 UCLA L. Rev. 376, 380 (2018) (describing how deal lawyers use preliminary agreements in M&A deals); Cathy Hwang, Faux Contracts, 105 Va. L. Rev. 1025, 1056 (2019) [hereinafter, Hwang, Faux Contracts] (describing how M&A deals create small relational ecosystems in which both the contracting parties and their agents are incentivized to engage in consummate, rather than perfunctory, performance). ↑
-
Ronald H. Coase, The Nature of the Firm, 16 Economica 386, 390 (1937) (posing and discussing the “boundaries of the firm” question: When should individuals be expected to form firms, and when should they be expected to cooperate through contract?). ↑